==============================
Please NOTE: There will be no new ECG Blog posts for a while ...
All material on this ECG Blog site remains open!
- The INDEX tab in the upper right of each page has linked Contents, listed by subject.
- IF you scroll down a little on the right-hand column of this blog — You'll see an icon for "ECG Audio PEARLS". This link takes you to 45 Audio Pearls, all of which are recent — and organized by topic.
- Just below the Audio Pearls — is an icon for "ECG Video PEARLS". Each of my recent 16 Video Pearls is downloaded onto this page for easy reference — again, organized by topic.
- If you are looking for material to review — I suggest you consider my most recent blog posts — which are linked to each of the Audio and Video Pearls.
 |
| Look for these icons for my Audio and Video PEARLS (scrolling down a bit in the right-hand column of each page). |

| THANK YOU all for your interest & support! — I'll be back! — |
==============================
ECG Blog #244 (MP-58) — The Cath Lab Was Activated. Agree?
==============================
The ECG in Figure-1 was obtained from a non-English speaking adult male, who presented with acute abdominal pain. The patient had a known history of diabetes — but because of the language barrier, the history was otherwise extremely limited.
- On seeing the ECG in Figure-1 — the cath lab was activated.
QUESTION:
- Should the cath lab have been activated?
- Explain your answer.
 |
| Figure-1: ECG obtained from a non-English speaking adult man with a history of diabetes and acute abdominal pain. The cath lab was activated. Do you agree? |
=======================================
NOTE: Some readers may prefer at this point to listen to the 8:30-minute ECG Audio PEARL before reading My Thoughts regarding the ECG in Figure-1. Feel free at any time to refer to My Thoughts on this tracing (that appear below ECG MP-58).
=======================================
Today's ECG Media PEARL #58 (8:30 minutes Audio) — Reviews some lesser-known Pearls for ECG recognition of Hyperkalemia.
MY Sequential Thoughts on the ECG in Figure-1:
As much as I "preach" the need to be systematic in ECG interpretation (as reviewed in detail in ECG Blog #205) — my "eye" was instantly drawn to several KEY findings for the ECG shown in Figure-1. This immediately suggested 2 ECG diagnoses to me.
QUESTION:
- What are the 2 ECG diagnoses that should come to mind within seconds of seeing the ECG in Figure-1?
ANSWER:
- A Brugada-1 ECG pattern is seen.
- Significant hyperkalemia is probably present.
PEARL #1: As important as a systematic approach to ECG interpretation is — the experienced clinician will with some ECGs immediately (almost automatically) know within seconds what is going on. When you encounter this — LISTEN to what the ECG is telling you. Sometimes this instinctive (almost automatic) diagnosis that you instantly "just know" may require immediate treatment (as when you see a wide tachycardia and know from the ECG appearance that the rhythm is VT). Therefore — Allow yourself a quick 5-10 seconds to "take in" any diagnosis that just "comes" to you. Then go back to the ECG — and complete your systematic interpretation.
- In Figure-1 — the importance of rapidly recognizing the Brugada-1 ECG pattern with probable severe Hyperkalemia is that: i) Immediate treatment of the hyperkalemia is needed; and, ii) Both of these conditions may dramatically alter ECG appearance in a way that will hinder systematic assessment if you don't realize these conditions are present. This happened in today's case — as initial providers mininterpreted the ECG in Figure-1 as suggestive of an acute STEMI, and therefore activated the cath lab.
The Brugada-1 ECG Pattern:
As illustrated and discussed in detail in ECG Blog #238 — the shape of the extreme (almost 10 mm) coved ST elevation in leads V1, V2 and V3, that terminates in T wave inversion is diagnostic of a Brugada-1 ECG pattern. This is especially true for the picture we see for the QRST complex in lead V1.
- This image of the QRST complex in lead V1 should be "engrained" in our brains — as a visual sign that immediately says, "I'm a Brugada-1 ECG pattern".
- While understandable that the overwhelming amount of ST elevation in anterior leads V1, V2 and V3 might prompt concern for a large anterior STEMI — the 2nd ECG diagnosis that our "experienced eye" has already made ( = hyperkalemia) — makes it much less likely that there would also be an ongoing STEMI.
- P.S. One might also misinterpret the rSR' in lead V1, with wide terminal S waves in leads I and V6 as consistent with RBBB. While true that this QRS morphology is consistent with RBBB — simple RBBB does not produce the ST segment shape that we see in each of the first 3 anterior leads, in which the dramatically elevated ST segments are coved (in V1,V2) and voluminous, taking a very delayed path in their descent toward final T wave inversion. NOTE: While I can not rule out the possibility that there is also underlying RBBB from this single tracing — what we know is that there is a Brugada-1 ECG pattern!
PEARL #2: As emphasized in ECG Blog #238 — a number of conditions other than Brugada Syndrome may temporarily produce a Brugada-1 ECG pattern. Among these other conditions — Hyperkalemia is perhaps the most common.
- Development of a Brugada-1 or Brugada-2 ECG pattern as a result of some other condition — with resolution of this Brugada ECG pattern after correction of the precipitating factor(s) is known as Brugada Phenocopy. The importance of recognizing Brugada Phenocopy — is that the risk of malignant arrhythmias is far less than it is for Brugada Syndrome.
- Regardless of whether one was still concerned that the ST elevation in Figure-1 might also represent an ongoing STEMI — Severe hyperkalemia would need to be treated before acute cath (and before any potential intervention for acute MI) could be contemplated. Therefore — the initial management approach to this patient is essentially defined within the few seconds it should take to recognize the severe hyperkalemia and Brugada-1 pattern on ECG (ie, promptly beginning with IV Calcium, even before lab confirmation returns).
- Whether the ECG changes in Figure-1 represent Brugada Phenocopy or Brugada Syndrome — and/or a STEMI — is almost certain to become apparent with ongoing monitoring of the serum K+ level — treatment of any other predisposing conditions — and through serial ECGs, that should show marked improvement, with resolution of ST elevation as serum K+ is corrected IF the ECG changes in Figure-1 are the result of Brugada Phenocopy.
The 2nd ECG Diagnosis = Severe HyperKalemia:
For clarity — I've added Figure-2, which presents the "textbook" sequence of ECG findings seen with progressive degrees of hyperkalemia. While fully acknowledging that "not all patients read the textbook" — and that there will be variations in the various ECG findings from one patient-to-the-next — I have found awareness of the generalizations for these ECG signs in Figure-2 to be extremely helpful.
- The usual earliest sign of hyperkalemia ( = T wave peaking) may begin with no more than minimal K+ elevation (ie, K+ between 5.5-6.0 mEq/L) — although in some patients, T wave peaking won't be seen until much later.
- I love the image of the Eiffel Tower. With progressive degrees of hyperkalemia — the T wave becomes tall, peaked (pointed) with a narrow base. While patients with repolarization variants or acute ischemia (including the deWinter T wave pattern) often manifest peaked T waves — the T waves with ischemia or repolarization variants tend not to be as pointed as is seen with hyperkalemia — and, the base of those T waves tends not to be as narrow as occurs with hyperkalemia.
- P.S. — As helpful as I find Figure-2 is for providing insight to the ECG changes we look for when suspecting clinically significant hyperkalemia — progression from sinus rhythm to VFib as the 1st ECG sign of hyperkalemia has been documented. Not all patients read the textbook. (emDocs, 2017 — Management of Hyperkalemia).
 |
| Figure-2: The "textbook" sequence of ECG findings with hyperkalemia. |
ECG Changes of Hyperkalemia in Today's Case:
The reasons I instantly suspected severe hyperkalemia in today's case were:
- Significant QRS widening (to at least 0.11 second in leads I, II, aVL and others).
- T wave morphology that is typical for hyperkalemia. As shown in Figure-3 — the T waves in multiple leads resemble the Eiffel Tower (ie, not only are the T waves in leads I, II, aVL; V4, V5 and V6 tall, peaked and pointed — but these T waves are symmetric with an equally steep angle of rise and fall — with a narrow T wave base).
- There is a Brugada-1 ECG pattern in leads V1, V2 and V3. As emphasized above — it is common to see Brugada Phenocopy in association with severe hyperkalemia.
Beyond-the-Core: Did YOU notice the "hump" in lead V3 (BLUE arrow). I believe what we are seeing in this lead is the pointed peak of what the T wave in lead V3 would have looked like — were it not obscured by the Brugada-1 pattern.
 |
| Figure-3: Take another look at the ECG in today's case. Don't YOU See the Eiffel Tower effect for the T waves in multiple leads? |
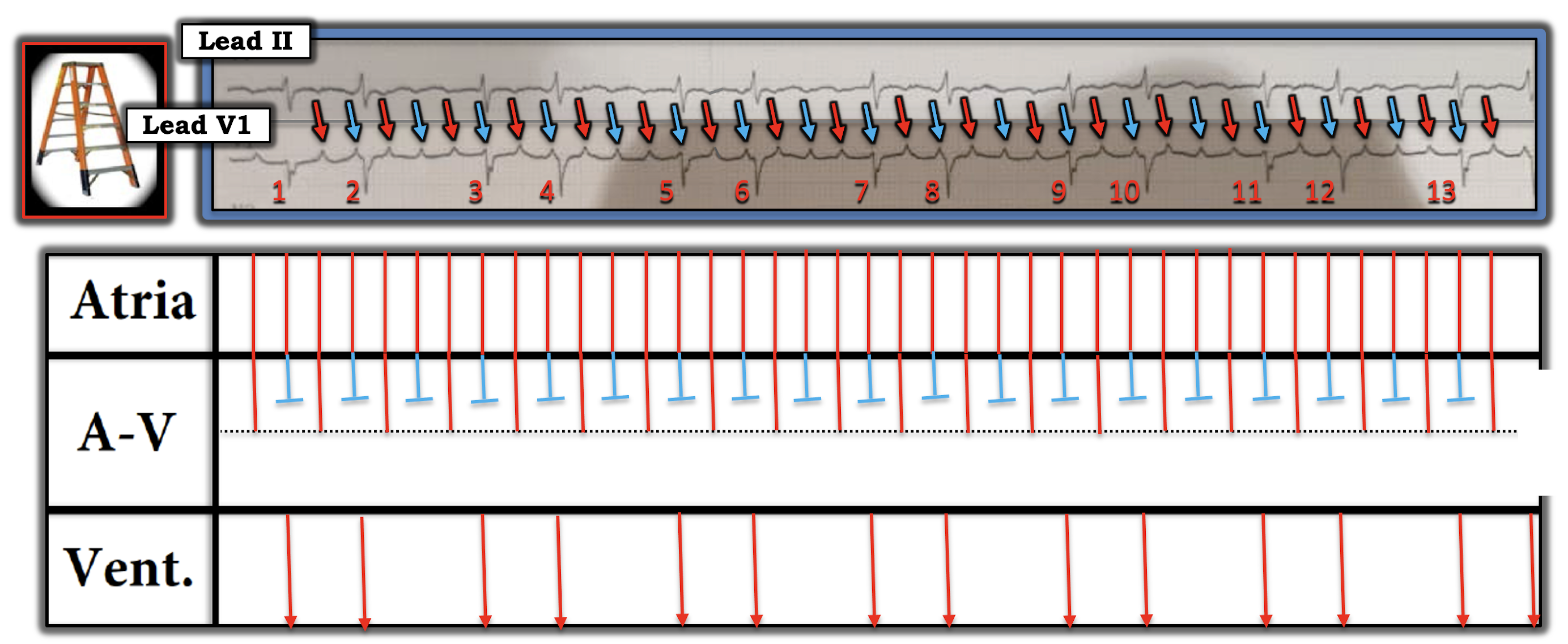
PEARL #3: Assessment of the rhythm with severe hyperkalemia is often extremely difficult because: i) As serum K+ goes up — P wave amplitude decreases, and eventually P waves disappear (See Panels D and E in Figure-2); ii) As serum K+ goes up — the QRS widens; and, iii) In addition to bradycardia — any form of AV block may develop, and AV conduction disturbances with severe hyperkalemia often do not "obey the rules" (See Figure-4).
- THINK for a MOMENT what the ECG will look like IF you can't clearly see P waves (or can't see P waves at all) — and the QRS is wide? ANSWER: The ECG will look like there is a ventricular escape rhythm, or like the rhythm is VT if the heart rate is faster.
- NOTE: We do not see P waves in most of the leads in Figure-3 — and it's difficult to be certain if the deflection in lead II is a sinus P wave (RED arrow). Fortunately — a definite P wave is seen in lead aVF, which confirms that the rhythm is still sinus (ie, sinus tachycardia at ~135/minute). But without lead aVF — I would not have been at all certain what the rhythm was.
 |
| Figure-4: Why assessing the rhythm with hyperkalemia is difficult (See text). |
Follow-Up to the Case:
The cardiac cath was negative (Clean coronary arteries! ). That said — the patient's condition precipitously declined after catheterization — and he was emergently intubated. Pertinent lab findings on admission included a pH = 6.94 — glucose over 1,100 mg/dL — serum K+ = 7.5 mEq/L.
- Fortunately — the patient's DKA (Diabetic KetoAcidosis) responded to treatment, with normalization of lab values.
- I was unable to obtain follow-up ECGs that could have confirmed my suspicion of Brugada Phenocopy.
==================================
Acknowledgment: My appreciation to David Didlake (from Texas, USA) for allowing me to use this case and these tracings.
==================================
Related ECG Blog Posts to Today’s Case:
- ECG Blog #205 — Reviews my Systematic Approach to 12-lead ECG Interpretation.
- ECG Blog #238 — Reviews Brugada Syndrome vs Brugada Phenocopy.
- The January 26, 2020 post in Dr. Smith's ECG Blog — Reviews a number of examples of hyperkalemia (with My Comment at the bottom of the page).
- The September 5, 2020 post in Dr. Smith's ECG Blog — Reviews another case of Brugada Phenocopy from Hyperkalemia (with My Comment at the bottom of the page).
- The April 25, 2020 post in Dr. Smith's ECG Blog — One more case Brugada Phenocopy from Hyperkalemia + "Shark Fin"-like ST Elevation (with My Comment at the bottom of the page).
- The October 21, 2020 post in Dr. Smith's ECG Blog — Reviews a case of Hyperkalemia which highlights the difficulty of determining the Rhythm (with My Comment at the bottom of the page).